För att möta behoven hos molntjänster delas nätverket gradvis in i Underlay och Overlay. Underlay-nätverket är den fysiska utrustningen, såsom routing och switching, i traditionella datacenter, som fortfarande tror på konceptet stabilitet och tillhandahåller tillförlitliga nätverksdataöverföringsmöjligheter. Overlay är det affärsnätverk som är inkapslat på det, närmare tjänsten, genom VXLAN- eller GRE-protokollinkapsling, för att ge användarna lättanvända nätverkstjänster. Underlay-nätverket och Ooverlay-nätverket är relaterade och frikopplade, och de är relaterade till varandra och kan utvecklas oberoende av varandra.
Underlagsnätverket är grunden för nätverket. Om underlagsnätverket är instabilt finns det inget servicenivåavtal för verksamheten. Efter trelagersnätverksarkitekturen och Fat-Tree-nätverksarkitekturen övergår datacentrets nätverksarkitektur till Spine-Leaf-arkitekturen, vilket inledde den tredje tillämpningen av CLOS-nätverksmodellen.
Traditionell nätverksarkitektur för datacenter
Trelagersdesign
Från 2004 till 2007 var treskiktsnätverksarkitekturen mycket populär i datacenter. Den har tre lager: kärnlagret (nätverkets höghastighetsväxlingsryggrad), aggregeringslagret (som tillhandahåller policybaserad anslutning) och åtkomstlagret (som ansluter arbetsstationer till nätverket). Modellen är följande:
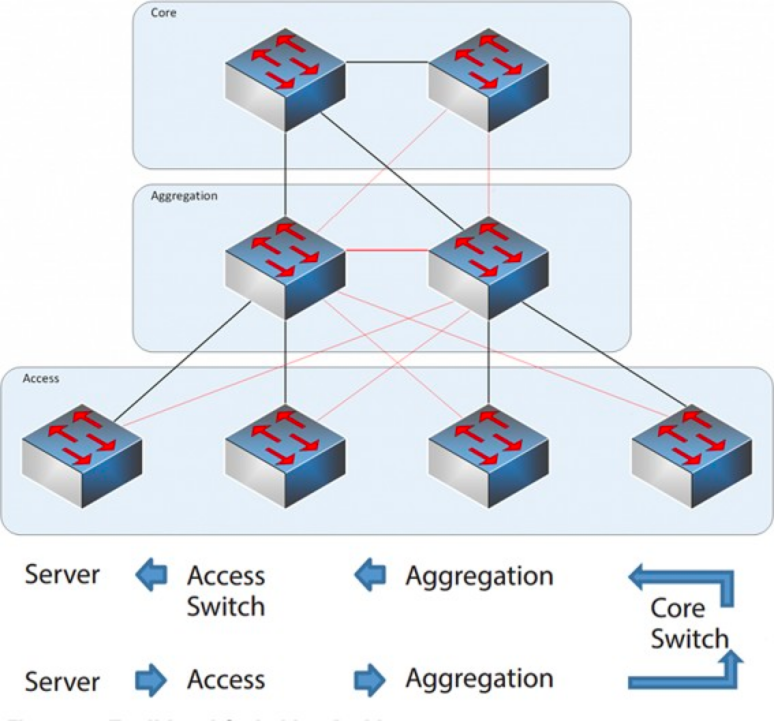
Treskiktad nätverksarkitektur
Kärnlager: Kärnswitcharna ger snabb vidarebefordran av paket in och ut ur datacentret, anslutning till flera aggregeringslager och ett robust L3-routingnätverk som vanligtvis betjänar hela nätverket.
Aggregeringslager: Aggregeringsväxeln ansluter till åtkomstväxeln och tillhandahåller andra tjänster, såsom brandvägg, SSL-avlastning, intrångsdetektering, nätverksanalys etc.
Åtkomstlager: Åtkomstswitcharna sitter vanligtvis högst upp i racket, så de kallas även ToR-switchar (Top of Rack), och de ansluter fysiskt till servrarna.
Vanligtvis är aggregeringsswitchen avgränsningspunkten mellan L2- och L3-nätverk: L2-nätverket ligger under aggregeringsswitchen och L3-nätverket ligger ovanför. Varje grupp aggregeringsswitchar hanterar en leveranspunkt (POD), och varje POD är ett oberoende VLAN-nätverk.
Nätverksslinga och Spanning Tree-protokoll
Bildandet av loopar orsakas oftast av förvirring orsakad av oklara destinationsvägar. När användare bygger nätverk använder de vanligtvis redundanta enheter och redundanta länkar för att säkerställa tillförlitlighet, så att loopar oundvikligen bildas. Layer 2-nätverket befinner sig i samma broadcastdomän, och broadcastpaketen kommer att sändas upprepade gånger i loopen, vilket bildar en broadcaststorm, vilket kan orsaka portblockering och utrustningsförlamning på ett ögonblick. För att förhindra broadcaststormar är det därför nödvändigt att förhindra bildandet av loopar.
För att förhindra loopbildning och för att säkerställa tillförlitlighet är det endast möjligt att omvandla redundanta enheter och redundanta länkar till backupenheter och backuplänkar. Det vill säga att redundanta enhetsportar och länkar blockeras under normala omständigheter och deltar inte i vidarebefordran av datapaket. Endast när den aktuella vidarebefordrande enheten, porten eller länken misslyckas, vilket resulterar i nätverksöverbelastning, öppnas redundanta enhetsportar och länkar, så att nätverket kan återställas till det normala. Denna automatiska kontroll implementeras av Spanning Tree Protocol (STP).
Spanning tree-protokollet fungerar mellan åtkomstlagret och sinklagret, och i grunden finns en spanning tree-algoritm som körs på varje STP-aktiverad brygga, vilken är specifikt utformad för att undvika bryggningsslingor i närvaro av redundanta sökvägar. STP väljer den bästa datavägen för att vidarebefordra meddelanden och tillåter inte de länkar som inte ingår i spanning tree, vilket lämnar endast en aktiv väg mellan två nätverksnoder och den andra upplänken blockeras.
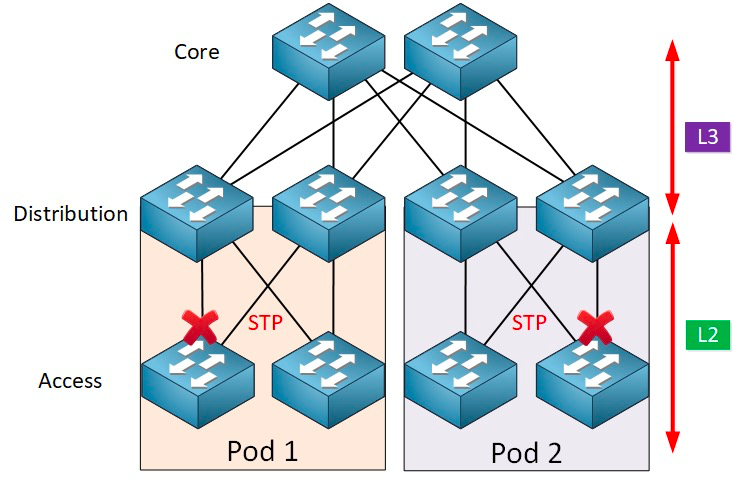
STP har många fördelar: det är enkelt, plug-and-play och kräver väldigt lite konfiguration. Maskinerna inom varje pod tillhör samma VLAN, så servern kan migrera platsen godtyckligt inom poden utan att ändra IP-adressen och gatewayen.
Parallella vidarebefordringsvägar kan dock inte användas av STP, vilket alltid kommer att inaktivera redundanta vägar inom VLAN:et. Nackdelar med STP:
1. Långsam konvergens av topologin. När nätverkstopologin ändras tar det 50–52 sekunder för spanning tree-protokollet att slutföra topologikonvergensen.
2, kan inte tillhandahålla lastbalanseringsfunktionen. När det finns en loop i nätverket kan spanning tree-protokollet bara blockera loopen, så att länken inte kan vidarebefordra datapaket, vilket slösar nätverksresurser.
Virtualisering och utmaningar med öst-västlig trafik
Efter 2010, för att förbättra utnyttjandet av dator- och lagringsresurser, började datacenter använda virtualiseringsteknik, och ett stort antal virtuella maskiner började dyka upp i nätverket. Virtuell teknik omvandlar en server till flera logiska servrar, där varje virtuell maskin kan köras oberoende, har sitt eget operativsystem, app, sin egen oberoende MAC-adress och IP-adress, och de ansluter till den externa enheten via den virtuella switchen (vSwitch) inuti servern.
Virtualisering har ett kompletterande krav: direktmigrering av virtuella maskiner, möjligheten att flytta ett system av virtuella maskiner från en fysisk server till en annan samtidigt som normal drift av tjänster på de virtuella maskinerna bibehålls. Denna process är okänslig för slutanvändare, administratörer kan flexibelt allokera serverresurser eller reparera och uppgradera fysiska servrar utan att påverka användarnas normala användning.
För att säkerställa att tjänsten inte avbryts under migreringen krävs det att inte bara den virtuella maskinens IP-adress förblir oförändrad, utan även att den virtuella maskinens körtillstånd (t.ex. TCP-sessionstillstånd) bibehålls under migreringen, så att den dynamiska migreringen av den virtuella maskinen endast kan utföras i samma lager 2-domän, men inte över lager 2-domänmigreringen. Detta skapar ett behov av större L2-domäner från åtkomstlagret till kärnlagret.
Skiljepunkten mellan L2 och L3 i den traditionella stora Layer 2-nätverksarkitekturen är vid kärnswitchen, och datacentret under kärnswitchen är en komplett broadcastdomän, det vill säga L2-nätverket. På så sätt kan man inse godtyckligheten i enhetsdistribution och platsmigrering, och behöver inte ändra konfigurationen av IP och gateway. De olika L2-nätverken (VLans) dirigeras via kärnswitcharna. Kärnswitchen under denna arkitektur behöver dock upprätthålla en enorm MAC- och ARP-tabell, vilket ställer höga krav på kärnswitchens kapacitet. Dessutom begränsar Access Switch (TOR) också skalan på hela nätverket. Detta begränsar så småningom nätverkets skala, nätverksexpansion och elasticitetsförmåga, vilket orsakar fördröjningsproblem över de tre schemaläggningslagen, vilket inte kan möta framtida affärsbehov.
Å andra sidan medför den öst-västliga trafiken som virtualiseringstekniken medför också utmaningar för det traditionella trelagersnätverket. Datacentertrafik kan i stort sett delas in i följande kategorier:
Nord-sydlig trafik:Trafik mellan klienter utanför datacentret och datacentrets server, eller trafik från datacentrets server till internet.
Öst-västlig trafik:Trafik mellan servrar inom ett datacenter, såväl som trafik mellan olika datacenter, såsom katastrofåterställning mellan datacenter, kommunikation mellan privata och publika moln.
Införandet av virtualiseringsteknik gör att distributionen av applikationer blir alltmer distribuerad, och "bieffekten" är att trafiken mellan öst och väst ökar.
Traditionella trenivåarkitekturer är vanligtvis utformade för nord-sydlig trafik.Även om den kan användas för öst-västlig trafik, kan den i slutändan inte fungera som krävs.
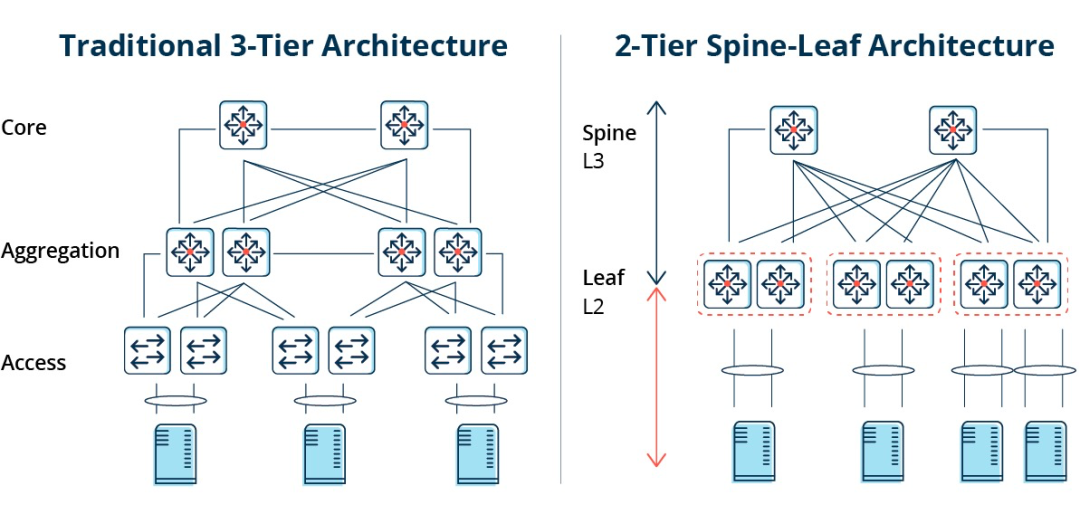
Traditionell trenivåarkitektur kontra Spine-Leaf-arkitektur
I en treskiktsarkitektur måste öst-västlig trafik vidarebefordras via enheter i aggregerings- och kärnlagren. Den passerar onödigtvis genom många noder. (Server -> Access -> Aggregation -> Core Switch -> Aggregation -> Access Switch -> Server)
Om en stor mängd öst-västlig trafik körs genom en traditionell treskiktad nätverksarkitektur kan därför enheter som är anslutna till samma switchport konkurrera om bandbredd, vilket resulterar i dåliga svarstider för slutanvändare.
Nackdelar med traditionell trelagers nätverksarkitektur
Det kan ses att den traditionella trelagersnätverksarkitekturen har många brister:
Bandbreddsslöseri:För att förhindra looping körs STP-protokollet vanligtvis mellan aggregeringsskiktet och åtkomstskiktet, så att endast en upplänk från åtkomstväxeln verkligen transporterar trafik, och de andra upplänkarna blockeras, vilket resulterar i slöseri med bandbredd.
Svårigheter vid storskalig nätverksplacering:Med utbyggnaden av nätverksskalan är datacenter distribuerade på olika geografiska platser, virtuella maskiner måste skapas och migreras var som helst, och deras nätverksattribut som IP-adresser och gateways förblir oförändrade, vilket kräver stöd av Fat Layer 2. I den traditionella strukturen kan ingen migrering utföras.
Brist på öst-västlig trafik:Treskiktsnätverksarkitekturen är huvudsakligen utformad för nord-syd-trafik, även om den även stöder öst-västlig trafik, men bristerna är uppenbara. När öst-västlig trafik är stor kommer trycket på aggregeringsskiktet och kärnskiktets switchar att öka kraftigt, och nätverkets storlek och prestanda kommer att begränsas till aggregeringsskiktet och kärnskiktet.
Detta gör att företag hamnar i dilemmat med kostnad och skalbarhet:Att stödja storskaliga högpresterande nätverk kräver ett stort antal konvergenslager- och kärnlagerutrustning, vilket inte bara medför höga kostnader för företag, utan också kräver att nätverket planeras i förväg vid byggandet av nätverket. När nätverksskalan är liten kommer det att orsaka slöseri med resurser, och när nätverksskalan fortsätter att expandera är det svårt att expandera.
Nätverksarkitekturen för ryggradsblad
Vad är Spine-Leaf-nätverksarkitekturen?
Som svar på ovanstående problem,En ny datacenterdesign, Spine-Leaf-nätverksarkitektur, har framkommit, vilket vi kallar leaf ridge-nätverk.
Som namnet antyder har arkitekturen ett ryggradslager och ett lövlager, inklusive ryggradsväxlar och lövväxlar.
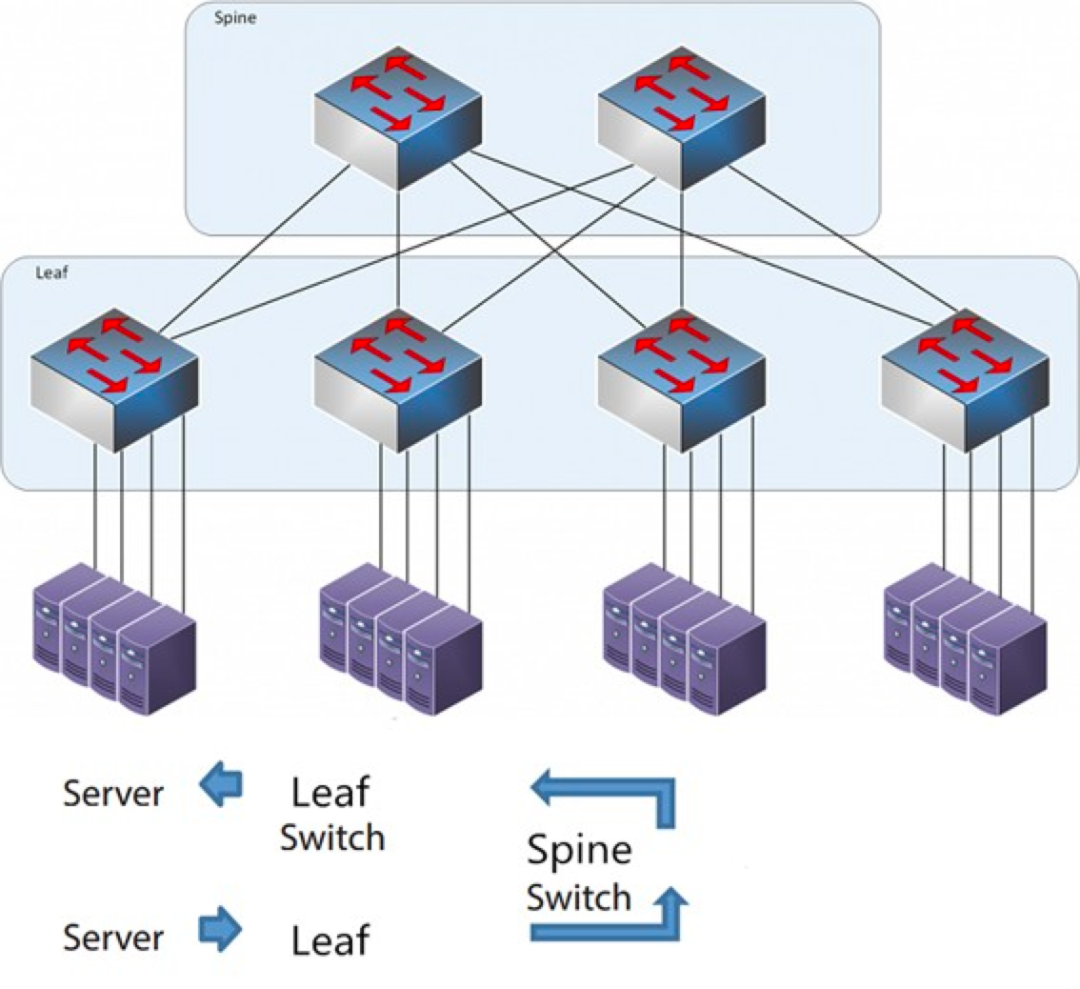
Ryggbladsarkitekturen
Varje bladströmbrytare är ansluten till alla åsströmbrytare, som inte är direkt anslutna till varandra, och bildar en full-mesh-topologi.
I spine-and-leaf-teknik passerar en anslutning från en server till en annan genom samma antal enheter (Server -> Leaf -> Spine Switch -> Leaf Switch -> Server), vilket säkerställer förutsägbar latens. Eftersom ett paket bara behöver gå igenom en spine och ett annat leaf för att nå destinationen.
Hur fungerar Spine-Leaf?
Leaf Switch: Den motsvarar åtkomstswitchen i den traditionella treskiktsarkitekturen och ansluter direkt till den fysiska servern som TOR (Top Of Rack). Skillnaden mot åtkomstswitchen är att avgränsningspunkten för L2/L3-nätverket nu finns på Leaf-switchen. Leaf-switchen är placerad ovanför treskiktsnätverket, och Leaf-switchen är placerad under den oberoende L2-sändningsdomänen, vilket löser BUM-problemet i det stora tvåskiktsnätverket. Om två Leaf-servrar behöver kommunicera måste de använda L3-routing och vidarebefordra det via en Spine-switch.
Spine Switch: Motsvarar en core-switch. ECMP (Equal Cost Multi Path) används för att dynamiskt välja flera vägar mellan Spine- och Leaf-switcharna. Skillnaden är att Spine nu helt enkelt tillhandahåller ett robust L3-routingnätverk för Leaf-switchen, så datacentrets nord-sydliga trafik kan dirigeras från Spine-switchen istället för direkt. Nord-sydlig trafik kan dirigeras från kantswitchen parallellt med Leaf-switchen till WAN-routern.
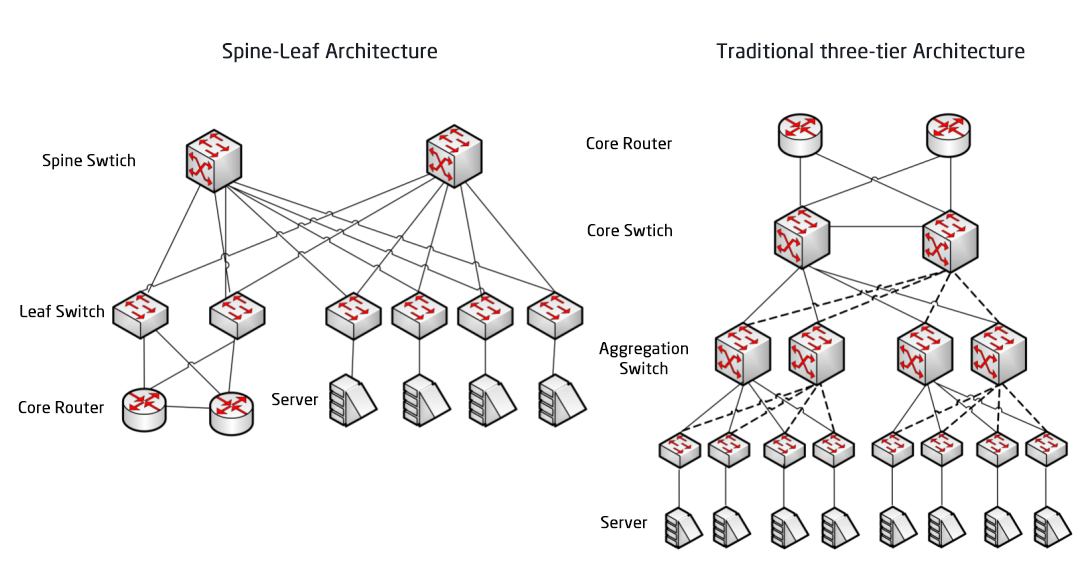
Jämförelse mellan Spine/Leaf-nätverksarkitektur och traditionell trelagersnätverksarkitektur
Fördelar med ryggradsblad
Platt:En platt design förkortar kommunikationsvägen mellan servrar, vilket resulterar i lägre latens, vilket avsevärt kan förbättra applikations- och tjänsteprestanda.
Bra skalbarhet:När bandbredden är otillräcklig kan en ökning av antalet ridge-switchar horisontellt utöka bandbredden. När antalet servrar ökar kan vi lägga till leaf-switchar om porttätheten är otillräcklig.
Kostnadsreduktion: Norrgående och södergående trafik, antingen utgående från lövnoder eller utgående från åsnoder. Öst-västligt flöde, fördelat över flera vägar. På så sätt kan lövåsnätverket använda fast konfigurationsväxlar utan behov av dyra modulära växlar, och därmed minska kostnaden.
Låg latens och undvikande av trängsel:Dataflöden i ett Leaf Ridge-nätverk har samma antal hopp över nätverket oavsett källa och destination, och två servrar kan nås från varandra via tre hopp. Detta skapar en mer direkt trafikväg, vilket förbättrar prestandan och minskar flaskhalsar.
Hög säkerhet och tillgänglighet:STP-protokollet används i den traditionella trenivåsnätverksarkitekturen, och när en enhet går sönder kommer den att återkonvergera, vilket påverkar nätverkets prestanda eller till och med sluta fungera. I leaf-ridge-arkitekturen, när en enhet går sönder, finns det inget behov av att återkonvergera, och trafiken fortsätter att passera genom andra normala vägar. Nätverksanslutningen påverkas inte, och bandbredden minskas bara med en väg, med liten prestandapåverkan.
Lastbalansering via ECMP är väl lämpat för miljöer där centraliserade nätverkshanteringsplattformar som SDN används. SDN möjliggör förenkling av konfiguration, hantering och omdirigering av trafik vid blockering eller länkfel, vilket gör den intelligenta lastbalanserande full-mesh-topologin till ett relativt enkelt sätt att konfigurera och hantera.
Spine-Leaf-arkitekturen har dock vissa begränsningar:
En nackdel är att antalet switchar ökar nätverkets storlek. Datacentret med en leaf ridge-nätverksarkitektur behöver öka antalet switchar och nätverksutrustning proportionellt mot antalet klienter. Allt eftersom antalet värdar ökar behövs ett stort antal leaf switchar för att länka upp till ridge-switchen.
Den direkta sammankopplingen av nock- och bladbrytare kräver matchning, och i allmänhet får det rimliga bandbreddsförhållandet mellan blad- och nockbrytare inte överstiga 3:1.
Till exempel finns det 48 stycken klienter med 10 Gbps hastighet på leaf-switchen med en total portkapacitet på 480 Gb/s. Om de fyra 40G-uplinkportarna på varje leaf-switch är anslutna till 40G Ridge-switchen, kommer den att ha en uplinkkapacitet på 160 Gb/s. Förhållandet är 480:160, eller 3:1. Datacenterupplänkar är vanligtvis 40 G eller 100 G och kan migreras över tid från en startpunkt på 40 G (Nx 40 G) till 100 G (Nx 100 G). Det är viktigt att notera att upplänken alltid bör köras snabbare än nedlänken för att inte blockera portlänken.
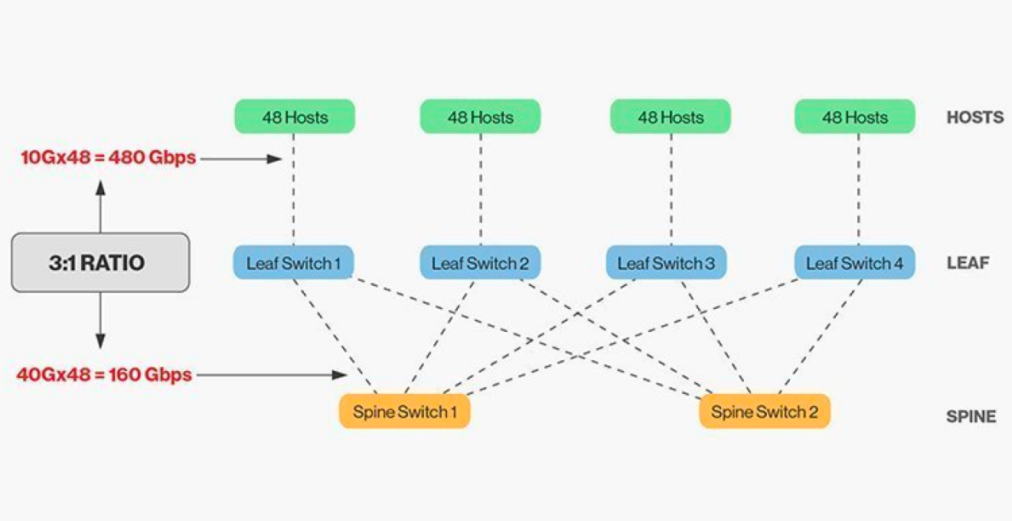
Spine-Leaf-nätverk har också tydliga krav på kabeldragning. Eftersom varje lövnod måste anslutas till varje spine-switch behöver vi lägga fler koppar- eller fiberoptiska kablar. Avståndet mellan sammankopplingarna driver upp kostnaden. Beroende på avståndet mellan de sammankopplade switcharna är antalet avancerade optiska moduler som krävs av Spine-Leaf-arkitekturen tiotals gånger högre än för den traditionella trenivåarkitekturen, vilket ökar den totala driftsättningskostnaden. Detta har dock lett till tillväxten av marknaden för optiska moduler, särskilt för höghastighetsoptiska moduler som 100G och 400G.
Publiceringstid: 26 januari 2026



